
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Python
- Java
- atlas
- MSA
- kubernetes
- 컨테이너
- OkHttpClient
- microservice
- MariaDB
- okhttp3
- 테이블정의서
- replaceAll
- spark
- 크롤링
- container
- REST
- docker
- 파이썬
- oracle
- 도커
- 쿠버네티스
- Prototype
- 스파크
- web crawl
- CRAWL
- Data Lineage
- dataset
- dataframe
- RDD
- 정규식
- Today
- Total
J 의 기록
[Spark] RDD, Dataset, DataFrame의 차이 본문
최근 회사에서 Elasticsearch 에서 Hive, Kudu, Hdfs로의 적재 모듈을 만들며 spark와 scala를 사용하였다.
그 중 spark를 사용하면서 rdd, dataset, dataframe 등의 개념에 대해 이해가 가지않아 회사 선배님께 여쭤본 결과
> dataframe: 정형 쪽에 가까움 (스키마가 있는..)
> rdd : 보다 비정형에 가깝고 개발자스러움(?)
라고 설명을 해주셨는데, 그 차이에 대해 알아보기로 했다.
먼저 spark에서 사용하는 Data Structure에는 여러 가지가 있다.
- RDD
- Dataset
- DataFrame
각각의 도입순서는 아래와 같다고 한다.
- RDD : Spark 1.0
- Dataset : Spark 1.6
- DataFrame : Spark 1.3
위에서 보았다시피 Dataset이 가장 최신 기술이다.
그럼 하나하나씩 특징들을 알아보자.
RDD
RDD는 Resilient Distributed Dataset 의 약자이다.
이름에서도 알 수 있듯이 분산된 데이터에 대한 자료구조이며
내가 읽은 책에서는 스파크에서의 모든 작업은 새로운 RDD를 만들거나, 존재하는 RDD를 변형하거나, 결과 계산을 위해 RDD에서 연산을 호출하는 것 중의 하나로 표현된다고 했다.
그만큼 RDD는 spark에 있어 핵심적인 개념이다.
또한 RDD의 특징으로
- MapReduce 작업이다.
- 병렬적으로 처리한다.
- 연산이 빠르다.
- Immutable (변경불가능? 불변) 하다.
- Transformation과 Action으로 함수 종류가 나눠지며, Action함수가 실행됬을때 실제로 연산이 실행된다.
- Lineage를 통해 Fault Tolerant (장애가 발생해도 운영에 지장을 주지 않는다. )를 보장한다.

DataFrame
Pandas 의 DataFrame과 유사하다.
그래서 그런지 DataFrame 관련 검색을 하면 pyspark와 DataFrame 관련 자료들이 많이 나왔다..
DataFrame의 특징은
- SparkSQL을 사용할 수 있다.
- RDD와 마찬가지로 Immutable 하다.
- Named Column 으로 구성되어있다.
- RDB Table 처럼 Schema를 가지고 있으며 RDB의 Table 연산이 가능하다.
- Catalyst Optimizer 를 통해 최적화가 가능하다?
특징들을 보니 회사 선배님이 말씀해주신 부분처럼 RDD와 달리 정형화되어있다는 생각이 든다.
조금 살펴보자면
SparkSQL을 사용할 수 있다.
이거에 대해 예를 들자면 scala에서 아래와 같이 사용이 가능하다.
val df = spark.sql("실행 Query")
RDD 와 파일을 쓰는 함수라든지 하는게 조금 차이가 났다.
이 부분에 대해서는 추가적으로 찾아봐야 할 것 같다..
Dataset
Spark 1.6에서 도입된 최신 기술.
나도 RDD와 DataFrame 에 대해 찾아보다가 알게되었다.
Spark 2.0에서는 DataFrame API가 Dataset API와 합쳐졌다고 한다.
RDD와 매우 유사한 특징을 갖지만
DataFrame과 같이 스키마의 컨셉이 포함되어 있는 데이터이다.
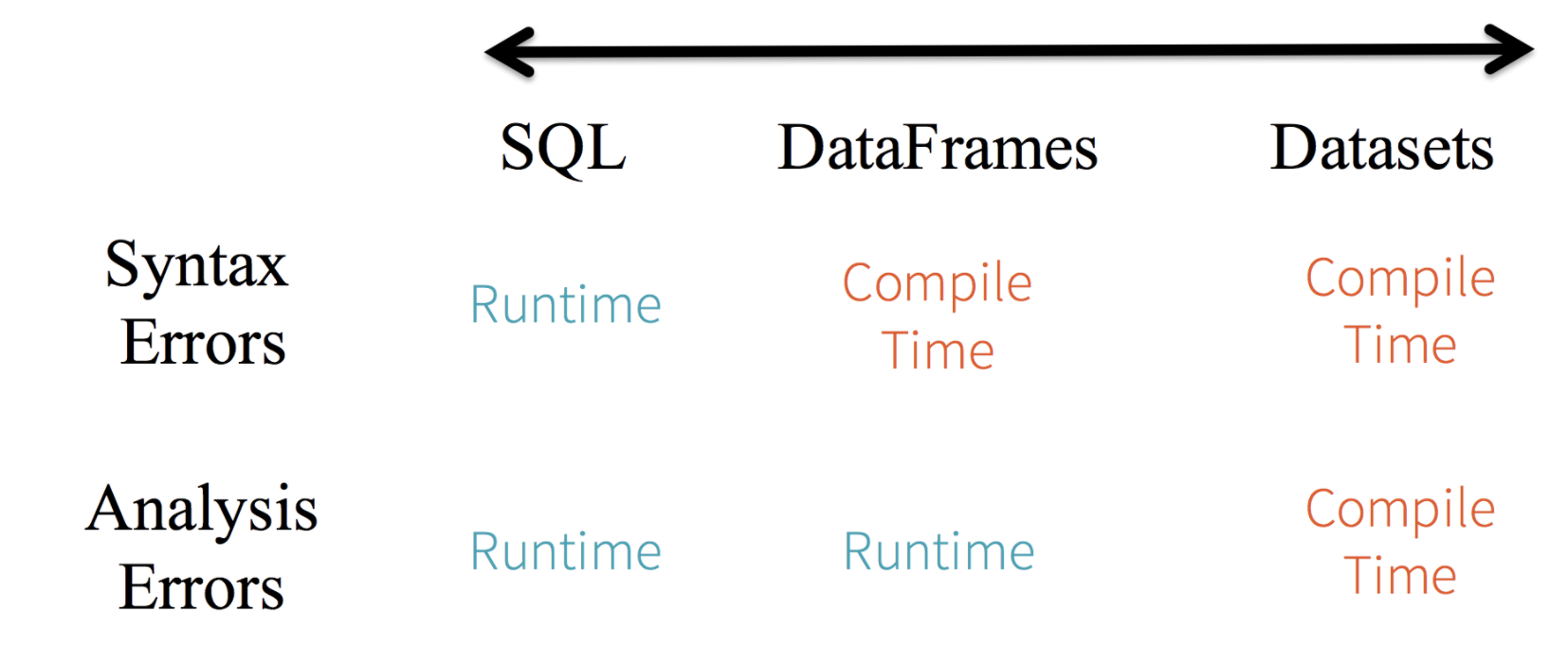
Dataset의 특징을 간략히 보자면
- RDD와 DataFrame의 장점을 취한다. (?)
- Type-safe하다.
- 마찬가지로 Catalyst Optimizer
- Query Plan이 작성된다..
써본적이 없어서 특징들을 봐도 잘 이해가 되지않는다.
Spark 2.0 이후 버전을 사용할 듯 하여 앞으로도 볼일이 없을 것 같다.
사용하는 날이 오게되면 그때 추가로 알아보도록 하겠다.
RDD vs DataFrame vs Dataset 언제 사용하는가
데이터를 직접적으로 핸들해야하는 경우 -> RDD (낮은 수준의 API 제공)
추상화된 API를 사용한 간결한 코드 작성 및 Catalyst Optimizer 를 통해 성능 향상을 꾀하고자 한다면 DataFrame 및 Dataset..
Scala / Java 개발자는 Encoder의 장점을 활용하는 Dataset을 권장한다고 한다..
+ Datasets은 JVM객체에 대한 바인딩으로 Encoder를 사용하여 유형별 JVM객체를 Tungsten의 내부 메모리 표현으로 매핑하게 된다. 결과적으로 Encoder를 통해 JVM객체를 효율적으로 직렬화/비직렬화 할 수 있으며 소형의 바이트 코드를 생성하게 됨으로 이는 cache size 축소 및 처리시간 관련 성능상 이점을 가질 수 있다. (출처 : https://www.popit.kr/spark2-0-new-features1-dataset/)
'개발' 카테고리의 다른 글
| [MSA] MSA (Microservices Architecture)란? (0) | 2021.01.04 |
|---|---|
| [Javascript] Javascript 에서 replaceAll() 구현하기 (0) | 2020.05.29 |
| [ES] Elastic Search - spark (1) (0) | 2020.04.08 |
| [Python] Python 크롤링 학습 - 1 (0) | 2020.04.08 |
| [Docker] 도커 컨테이너 (0) | 2020.03.09 |


